이 포스트는 Udacity - DLFND를 강의 내용을 필기 형식으로 작성 했습니다.
Regression
이번 주제는 Regression[회귀] 입니다.
Linear Regression
하나의 입력으로 원하는 값을 예측할 때 사용할 수 있습니다.
예를들어, 내가 공부한 시간으로 시험에서 내가 몇점을 받을지 예측해 보는것 입니다.
아래는 sklearn을 사용한 Linear Regression 소스 코드 입니다.
예제코드
from sklearn.linear_model import LinearRegression
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 Import
data = pd.read_csv('./score.csv', delimiter='\t')
quantity = data[['quantity']] # 공부량
quality = data[['quality']] # 공부의 질 ex) 집중도
score = data[['score']] # 점수
# Linear Regression 모델 생성
model = LinearRegression()
# 모델 Fit
model.fit(quantity, score)
# 예측 해보기
my_quantity = 20 # 내가 공부한 량
predict = model.predict(my_quantity)
print(predict) # [[ 69.61268266]]
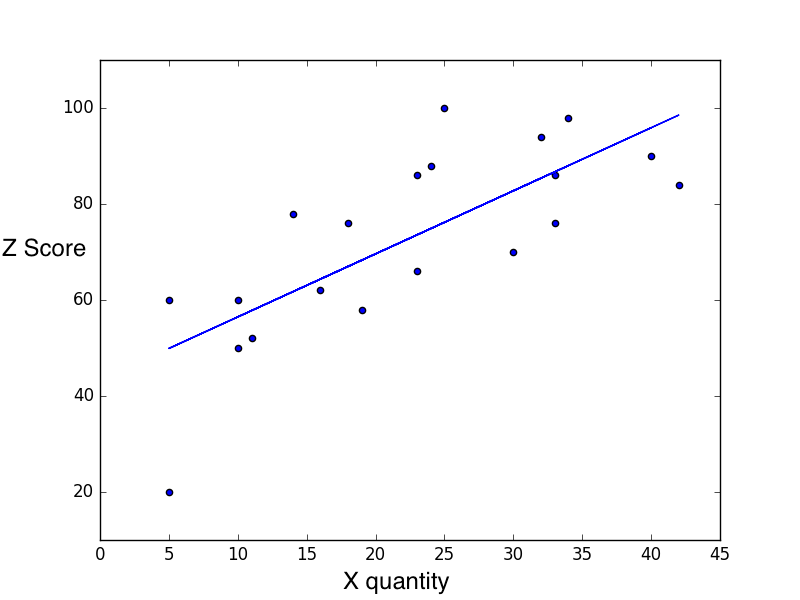
## 2D Visualization
plt.scatter(quantity, score)
plt.plot(quantity, model.predict(quantity))
plt.show()« 데이터 셋 »
# ex) one_two.csv
Name quantity quality score
a 10 3 50
b 23 4 86
c 14 5 78
d 32 3 94
e 23 2 66
f 40 1 90
g 10 4 60
h 11 3 52
i 34 3 98
j 30 1 70
k 33 1 76
l 42 0 84
m 5 1 20
n 24 4 88
o 33 2 86
p 5 5 60
q 18 4 76
r 19 2 58
s 16 3 62
t 25 5 100« 그래프 표시 »
Linear Regression Warnings
선형 회귀 문제점
- 데이터가 선형으로 흩어져 있을때만 잘 동작한다.
– Solution: 1_데이터를 보정하여 선형으로 만든다. 2_Feature를 추가한다. 3_다른 모델을 사용한다. - 선형 회귀는 Outliers 에게 민감합니다.
– Solution: 1_전처리에서 Outliers 제거
«참고 사진»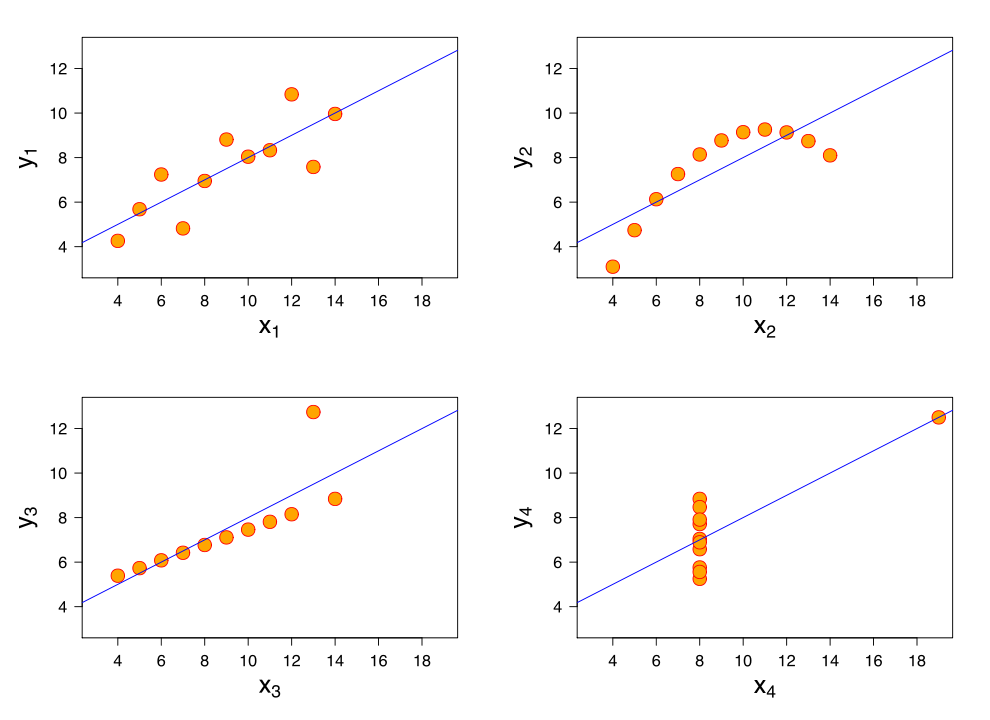
Multiple Linear Regression
여러개의 입력으로 원하는 값을 예측할 때 사용할 수 있습니다.
예를들어, “공부 시간” 뿐만 아니라 “집중도”도 함께 데이터 추가하여 점수를 예측해 보는 것 입니다.
공부량만으로 점수를 예측한 것보다 정확한 결과를 얻을 수 있을것 같습니다.
아래는 sklearn을 사용한 Multiple Linear Regression 소스 코드 입니다.
예제 코드
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
from matplotlib import pyplot as plt
# 데이터 Import
data = pd.read_csv('./score.csv', delimiter='\t')
quantity_and_quality = data[['quantity','quality']]
score = data[['score']]
# Linear Regression 모델 생성
model = LinearRegression()
# 모델 Fit
model.fit(quantity_and_quality, score)
# 예측 해보기
my_quantity_and_quality = [[20,3]] ## 예) 20시간 공부하고, 집중도는 3
predict = model.predict(my_quantity_and_quality)
### 3D Visualization ###
# 1) 데이터 점 찍기
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for c, m, zlow, zhigh in [('r', 'o', -50, -25), ('b', '^', -30, -5)]:
xs = data[['quantity']]
ys = data[['quality']]
zs = data[['score']]
ax.scatter(xs, ys, zs, c=c, marker=m)
ax.set_xlabel('X quantity')
ax.set_ylabel('Y quality')
ax.set_zlabel('Z score')
# 2) 함수에서 사용할 데이터 생성
X = np.arange(-1, 51, 0.25) # X범위 (시작, 끝, 간격)
Y = np.arange(-1, 6, 0.25) # Y범위 (시작, 끝, 간격)
X, Y = np.meshgrid(X, Y) # X 와 Y 짬뽕
Z = 2*X+10*Y # <-----------공식 만들기
# 3) 함수 그리기 (Surface)
surf = ax.plot_surface(X, Y, Z, cmap=cm.coolwarm,
linewidth=0, antialiased=False, alpha=0.5)
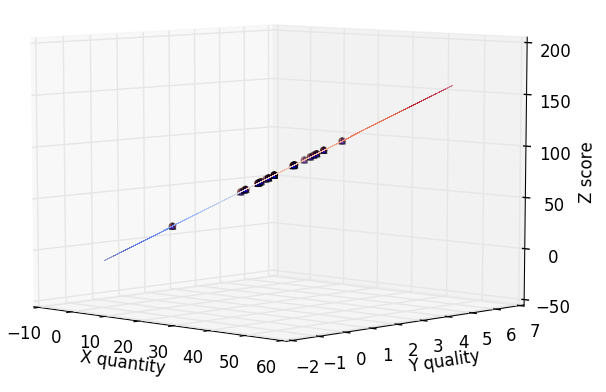
plt.show()« 그래프 표시 »
- 공부량과 시험점수 2D 표시
- 공부량과 시험점수 3D 표시_1
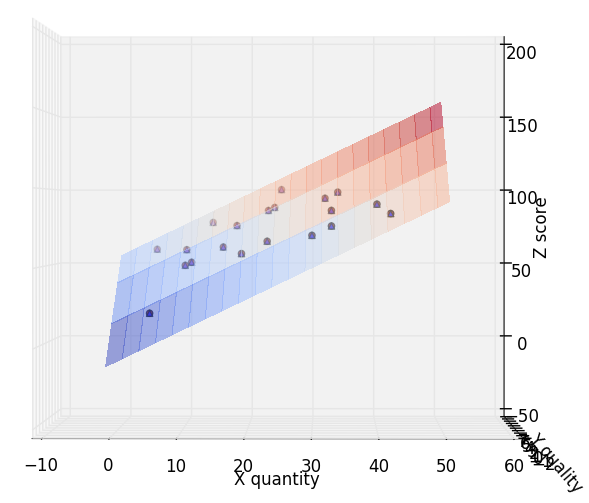
- 공부량과 시험점수 3D 표시_2
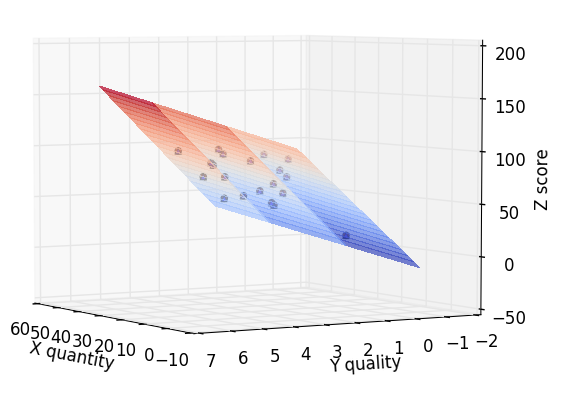
- 공부량과 시험점수 3D 표시_3

- 데이터가 한 평면에 나타난 것을 확인
Multiple Linear Regression (보스턴 부동산 가격 예측)
Multiple Linear Regression 은 2개 이상의 입력을 사용한 데이터 예측 예제 입니다.
13가지의 입력으로 부동산 가격을 예상합니다.
아래는 sklearn에서 보스턴 부동산 가격 데이터셋으로 Multiple Linear Regression 소스 코드 입니다.
예제 코드
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
# sklearn에서 제공하는 데이터 셋
boston_data = load_boston()
x = boston_data['data']
y = boston_data['target']
print(x.shape, y.shape) ## (506, 13) (506,) ## 데이터셋 shape
# 모델 생성
model = LinearRegression()
# Multiple Linear Regression
model.fit(x,y)
# 예측 해보기
sample_house = [[2.29690000e-01, 0.00000000e+00, 1.05900000e+01, 0.00000000e+00, 4.89000000e-01,
6.32600000e+00, 5.25000000e+01, 4.35490000e+00, 4.00000000e+00, 2.77000000e+02,
1.86000000e+01, 3.94870000e+02, 1.09700000e+01]]
prediction = model.predict(sample_house)
print(prediction)