TESTING IN SKLEARN
from sklearn.model_selection import train_test_split
x = (1,2,3,4,5,6,7,8)
y = (1,2,3,4,5,6,7,8)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size = 0.25)
print(x_train, x_test)
print(y_train, y_test)
##
output:
[3, 4, 1, 8, 2, 7] [6, 5]
[3, 4, 1, 8, 2, 7] [6, 5]MEAN ABSOLUTE ERROR IN SKLEARN
구분선과의 절대값으로 error 측정
ex)
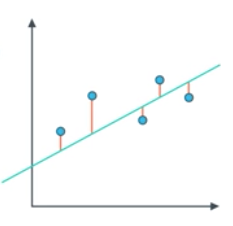
import numpy as np
from sklearn.metrics import mean_absolute_error # 구분선과의 거리
from sklearn.linear_model import LinearRegression
x = np.array([[1,2,3,4,5,6,7,8]])
y = np.array([[1,2,3,4,5,6,7,8]])
classifier = LinearRegression()
classifier.fit(x, y)
guesses = classifier.predict(x)
error = mean_absolute_error(y, guesses)MEAN SQUARED ERROR IN SKLEARN
구분선과의 제곱값으로 error 측정
ex)
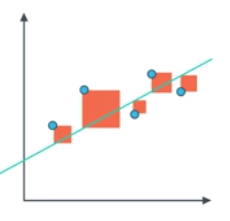
import numpy as np
from sklearn.metrics import mean_squared_error # 구분선과의 거리
from sklearn.linear_model import LinearRegression
x = np.array([[1,2,3,4,5,6,7,8]])
y = np.array([[1,2,3,4,5,6,7,8]])
classifier = LinearRegression()
classifier.fit(x, y)
guesses = classifier.predict(x)
error = mean_squared_error(y, guesses)
print(error)R2 SCORE IN SKLEARN
통계학에서, 결정계수(決定係數, 영어: coefficient of determination)는 추정한 선형 모형이 주어진 자료에 적합한 정도를 재는 척도이다. 반응 변수의 변동량 중에서 적용한 모형으로 설명가능한 부분의 비율을 가리킨다. 결정계수의 통상적인 기호는 R2 이다.
from sklearn.metrics import r2_score
y_true = [1,2,4]
y_pred = [1.3, 2.5, 3.7]
print(r2_score(y_true, y_pred))CROSS VALIDATION IN SKLEARN
Machine Learning을 할때 사용자가 가지는 데이터는 오직 훈련집합(Training set) 과 테스트집합(Test set) 뿐이다. 집합내에 샘플의 수가 굉장히 많다면 물론 좋겠지만, 실제상황에서 샘플수가 무한정 제공 될 수는 없다. 따라서 데이터의 양이 충분치 않을 때, 분류기 성능측정의 통계적 신뢰도를 높이기 위해서 쓰는 방법이 재샘플링(resampling) 기법을 사용하는데 대표적인 방법으로는 k-fold cross validation
출처: 처음의 마음
import numpy as np
from sklearn.model_selection import KFold
X = np.array([[10, 20], [30, 40], [50, 60], [70, 80]])
y = np.array([10, 20, 30, 40])
kf = KFold(n_splits=5)
KFold(n_splits=2, random_state=None, shuffle=False)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "| TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
#print("X_train:", X_train)
#print("X_test:", X_test)
#print("Y_train:", y_train)
#print("Y_test:", y_test)
'''
output:
TRAIN: [1 2 3] | TEST: [0]
TRAIN: [0 2 3] | TEST: [1]
TRAIN: [0 1 3] | TEST: [2]
TRAIN: [0 1 2] | TEST: [3]
'''